")
The Linux csplit command is a versatile utility used to split a file into multiple segments based on specified context lines or patterns. Unlike the split command, which divides files based on size, csplit allows users to define split points using line numbers, regular expressions, or a combination of both, making it ideal for handling text files with a predictable structure. The command generates output files named sequentially, with a default prefix and numeric suffixes, which can be customized. This flexibility is particularly useful for tasks such as extracting sections from log files, breaking up configuration files, or preparing text data for processing by other scripts or applications.
In this tutorial, we will discuss the basics of this tool and learn how to use it. But before we do that, it’s worth mentioning that all commands/instructions mentioned here have been tested on Ubuntu 24.04.
Linux Csplit command
Here’s how the command’s man page defines it:
csplit - split a file into sections determined by context lines
Following is its generic syntax:
csplit [OPTION]... FILE PATTERN...
The individual small files created by csplit have names like xx00 and xx01. The following definition – taken from the command’s man page – should make things more clear:
Output pieces of FILE separated by PATTERN(s) to files 'xx00', 'xx01', ..., and output byte
counts of each piece to standard output.
The following Q&A-type examples should give you a good idea about how the csplit command works.
Q1. How to split files based on number of lines?
Suppose your file contains six lines, and the requirement is to split that file at the third line. This can be done by passing ‘3’ as a command line argument after the command and file name.
For example, in our case, file1 contained the following lines:
1 Asia
2 Africa
3 Europe
4 North America
5 South America
6 Australia
And here’s the command we executed:
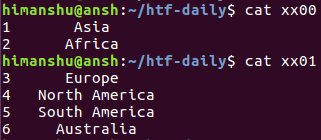
csplit file1 3
The numbers produced in the output are the byte count for the files the command produced. Two files were produced in the output, namely xx00 and xx01.
The contents of these files confirm the split happened at line number 3.
Q2. How to split files using regular expressions?
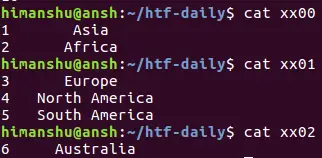
You can also use regular expressions with the csplit command. For example, in the previous case, if you want the tool to repeat the pattern one more time, then you can do this using the following command:
csplit file1 3 {1}
So in this case, three output files were produced:
Q3. How to have custom prefix instead of the default ‘xx’?
By default, the files that csplit produces in output have ‘xx’ as the prefix. However, if you want, you can change the prefix using the -f command line option, which requires the new prefix as its input.
For example, the following command will produce files having ‘htf’ as prefix.
csplit file1 1 -f htf
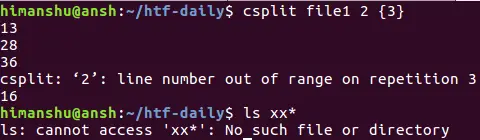
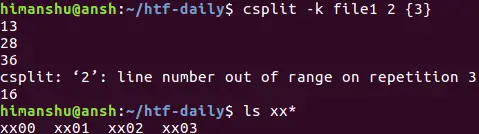
Q4. How to force csplit not to remove output files in case of error?
The csplit command, by default, removes output files (any, if created) as soon as an error is encountered. For example, the following screenshot confirms no output file was eventually produced:
However, you can change this behavior by using the –k option in the command. For example, the same command was executed again, but with this option, and the output files were not deleted this time.
Q5. How to suppress lines that match input pattern?
The csplit command also allows suppressing lines that match the input pattern. The option in question is –suppress-matched.
For example, the following command splits the file (file1) at line 2 (xx00 will contain line 1, while xx11 will contain rest of the lines).
csplit file1 2
But if you want to suppress line 2, then you can run the following command:
csplit --suppress-matched file1 2
Q6. How to use custom number of digits instead of the default 2?
Just like the prefix itself, the number of digits that follow prefix in the output filenames is also customizable. So suppose you want to have names like xx000 and xx0001, you can do this using the -n command line option, which requires an input number signifying the new number of digits.
For example:
csplit -n 1 file1 2
The above command would produce file names like xx0, xx1, etc.
Conclusion
An average Linux command line user may not require split on a daily basis, but it’s an important utility that you should at least know about. We’ve covered most of the basic examples and command line options here. Try them out, and then head to the tool’s man page to learn more about it.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}